Prelude
Check out the first part of this series, of course. This article won’t feature too much on the interpreter design, but how to effectively use it to your own benefit.
TL;DR, I tried to write an IGCSE pseudocode interpreter a while ago, and I finished! Find it here at https://github.com/ezntek/beancode. Or, install it directly with pip install beancode --break-system-packages (this will not break your system packages, because beancode has no system dependencies, and will not break anything despite the scary flag)
Jump here if you only want to learn about the special and extra features of the interpreter and functional quirks.
Intro
I published my first article almost a year ago; on the 18th of September, 2024. It is now the 13th September, 2025. What’s happened since then?
Well, a lot of school stuff. I was in grade 10 at the time, with quite a bit of spare time. However, I just didn’t get around to doing much of anything!
Originally I wanted to write a pseudocode compiler in C, but I got stuck at the parser. If you look at my really old code somewhere in https://github.com/ezntek/beanwarehq, I actually tried to write a bottom-up parser. Young ezntek really did discover another parsing technique just then, however implemented horribly and barely functional.
I then tried to write one in Zig. In one afternoon I ported the lexer over, but that didn’t end up going anywhere. Sometime during march of this year, I just had enough waiting; I had a bunch of other projects and a lot of schoolwork to do (I am, after all, a leader of the computer programming club at my school, and the author of a bunch of IGCSE CS revision resources), but I really just wanted to get something done.
I tried to follow Crafting Interpreters…in Python. I knew the language, it was slow, horrible, but great for doing hacky stuff like the thing I envisioned (just a single top-down recursive-descent parser), and that ended up going…really well.
So what do we have now?
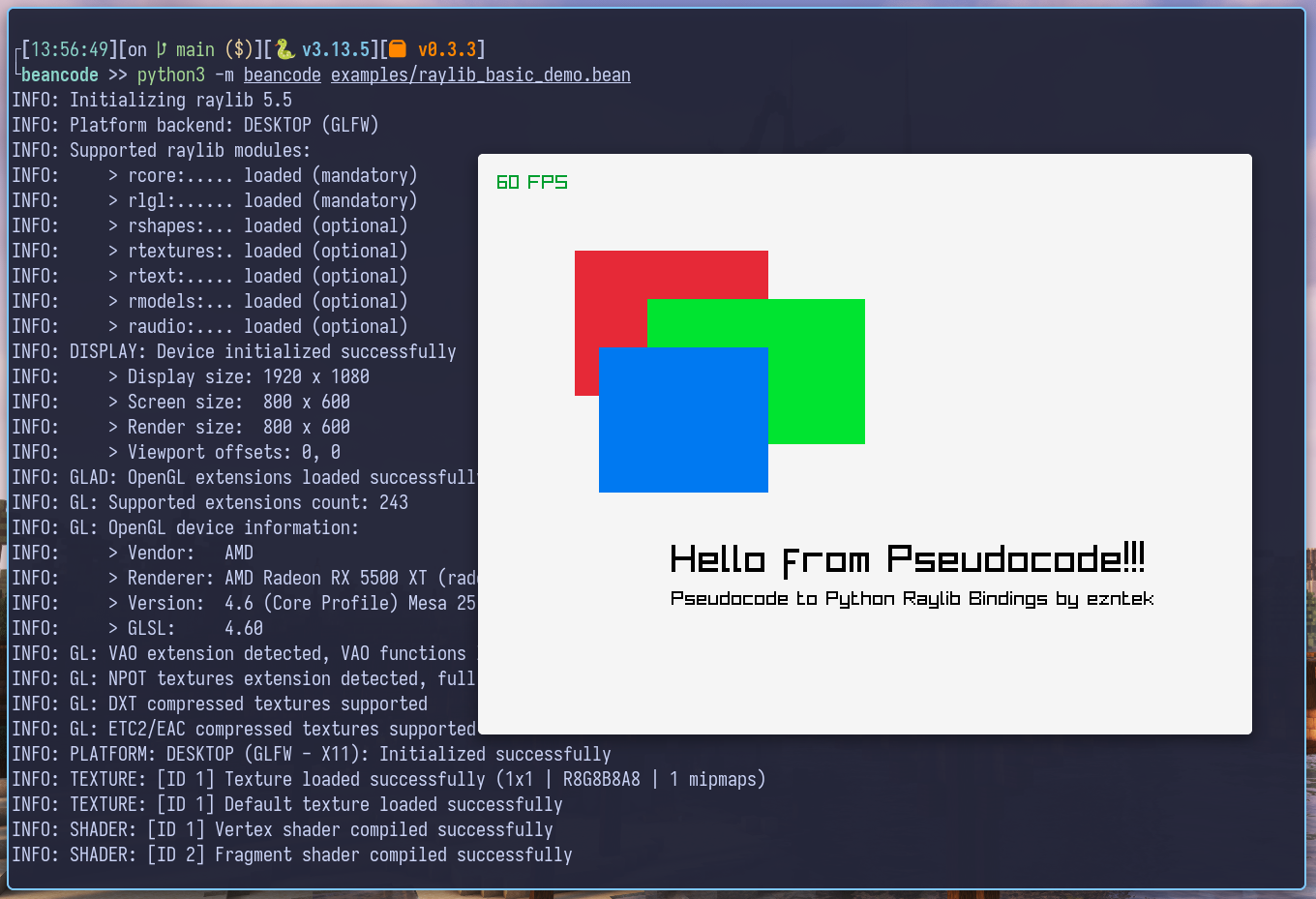
…what? By the way, yes, it is running on my interpreter. It’s called beancode. Grab it here; it’s called beancode. Here’s the source code for the demo:
INCLUDE_FFI "beanray"
CALL InitWindow(800, 600, "hello, world!")
CALL SetTargetFPS(60)
WHILE NOT WindowShouldClose() DO
CALL BeginDrawing
CALL ClearBackground(RAYWHITE)
CALL DrawFPS(20, 20)
CALL DrawRectangleRec({ 100, 100, 200, 150 }, RED)
CALL DrawRectangleRec({ 175, 150, 225, 150 }, GREEN)
CALL DrawRectangleRec({ 125, 200, 175, 150 }, BLUE)
CALL DrawText("Hello from Pseudocode!!!", 200, 400, 40, BLACK)
CALL DrawText("Pseudocode to Python Raylib Bindings by ezntek", 200, 450, 20, BLACK)
CALL EndDrawing
ENDWHILE
CALL CloseWindow
Architecture
This program is actually very simple. Now, I will elaborate on the architecture in a later post, and post design-related shotcomings. This is the overall structure:
- Lexer
- Parser
- Interpreter
For those who know, this is a tree-walking interpreter. Basically, the source file is parsed into a tree-like data strcuture which represents the source file’s layout and structure. Then, the structure is traversed by Python to evaluate expression adn to do stuff.
Lexer
The lexer is quite stupid. You can find it in beancode/lexer.py. It is so stupid and scuffed that it doesn’t even support streaming tokens properly (although I could hack it in, in theory). It also does really weird stuff. There’s logic in the lexer that actually does some “parsing” because this was a hasty AF fix.
-4 is treated as a single literal -4 and not minus, literal(4). Wow! I forgot why I did this honestly…
Otherwise, it works…barely. It is also really bad at detecting unterminated string literals. At some point it just screams and gives up on reporting proper position data.
Parser
The parser is equally as cursed, if not more than the parser. It is recursive-descent and does not use any precedence tables (what the hell are those). Position data reporting is cursed as hell, but whatever. It cannot detect many parsing errors at once, it will stop whenever it sees an error. It also doesn’t use the consume and expect pattern that I later learned about, its more like:
token = self.consume()
if token.kind != <wanted kind>:
raise BCError(f"expected <token kind>, but got {token}", token.pos)
You will see this pattern literally everywhere :>
Interpreter
This is super scuffed as well. Intrinsics (i.e. “Library Routines” as Cambridge calls them) are implemented literally as Python functions, dispatched with a massive switch-case. The number of arguments are literally just stored in a global hash map. I could go on for hours regarding the cursedness of this thing and how many hacks this thing has implemented. It does literally no optimizations, and global and local variables behave VERY WEIRDLY.
The REPL
The REPL works on a bunch of input statements. Since each component so far was a reusable class that I could call intermediate methods on, I just stitched them together to make a REPL. I abused Python’s readline module a lot for basic REPL features like shell history, and moving around in the current input buffer.
- Each line is fed into the lexer, and then parser, and run in a global interpreter context.
- If EOF is reached during parsing or lexing, the parser throws an exception with the
eofflag set toTrue. The REPL then catches the exception and enters continuation mode.- The usual prompt is
>>, but for continuation mode, it is... The current input buffer before the continuation is saved in aStringIO, and every time a new line is entered, the parser tries to analyze the entire input so far, and then keeps going if EOF is reached. Otherwise, it returns back to the parent main REPL runner.
- The usual prompt is
- Position reporting actually works! (Surprisingly, errors work fine for the most part).
- Some errors report as having position
line 0, column 0, which is a really annoying feature I left in because I didn’t want to null the position field in the error class. I’ll fix it if it’s actually that bad.
Extension Features
I will from now assume that you know how to write Pseudocode.
- You can use lowercase keywords! Begone the days of screaming your code, you can just write lowercase words like
for,next,if,while, etc. - You can include other beancode files with
INCLUDE "filename", which is the file name you want to include, with the extension.- Mark a symbol (variable declaration, constant, procedure or function) with
EXPORTto dump it into the current scope. There are no namespaces! - You can even include FFI modules with
INCLUDE_FFI. They have to be the bundled modules, though.beanrayis an incomplete set of raylib bindings that supports some basic examples.beanstdis a very small std library with some basic functinoality.demo_ffimodis just a demo FFI module as a proof-of-concept.
- Mark a symbol (variable declaration, constant, procedure or function) with
- Mark custom scopes with
SCOPEandENDSCOPE. You can also export from them. - There are a bunch of added intrinsics. Check them out in the README on the GitHub repo.
- You can type cast with
TYPE(expr) - You can declare and assign on the same line, if you really need to.
- You don’t even have to specify the type:
DECLARE Num: INTEGER <- 5 DECLARE Num <- 4 - I added a bunch of neat type inference features.
Num <- 4is equal toDECLARE Num: INTEGER <- 4.- If you have a declared variable, it will be able to guess the type too.
- You can
INPUTinto an undeclared variable, and it will “insert a declaration” and then store your input into the new variable.
- Array literals!
Arr <- {1, 2, 3, 4, 5}is anARRAY[1:5] OF INTEGER
- Matrix literals!
Mat <- {{1, 2}, {4, 5}, {7, 6}}is anARRAY[1:3,1:2]OF INTEGER
- There is some introspection/reflection. You can get the type of any variable with
TYPE(value)orTYPEOF(value)(case-insensitive)
Quirks
- You cannot have multiple lines in a
CASE OFstatement. You have to put your code into a procedure. - File I/O does not work at all.
- Some errors report as
unused expressionorinvalid statement or expression. - Reported errors will look a little different on Windows (ASCII only chars), thanks to its horrible unicode support. F*** you, Micros*ft!
Scope
All variables are global. They will infect all sub-scopes. For example:
DECLARE A: INTEGER
// In scope: A
SCOPE
DECLARE B: INTEGER
// In scope: A, B
SCOPE
DECLARE C: INTEGER
// In scope: A, B, C
ENDSCOPE
ENDSCOPE
When a new block is created, all the pointers to outside variables are copied to the current sub-interpreter’s variable pool. This works the exact same for procedures. You cannot have truly local variables, and you cannot shadow a declaration of an outside variable with a local variable.
The REPL
The REPL is a truly life-changing innovation. Simply launch beancode without any arguments and you will be dropped in a REPL, and you can start typing code. Expressions will be printed.
The REPL also has special features which lets you see the state of the interpreter. You can talk to the REPL and not the interpreter with dot commands. Here are the very important ones.
.vargets information regarding an existing variable. It prints its name, type, and value..varsprints information regarding all variables..funcgets information regarding existing functions or procedures..funcsprints information regarding all functions and procedures.- Delete a variable if you need to with
.delete [name]. (Version0.3.4and up) - Or, reset the entire interpreter’s state with
.reset.
History is saved to ~/.beancode_history.
Performance
Performance is at the mercy of the Python implementation. From my GitHub page:
It’s really bad. However, PyPy makes it a lot better. Here’s some data for the PrimeTorture benchmark in the examples, ran on an i7-14700KF with 32GB RAM on Arch Linux:
Language Time Taken (s) beancode (CPython 3.13.5) 148 beancode (PyPy3 7.3.20) 11 beancode (CPython Nuitka) 185 Python (CPython 3.13.5) 0.88 Python (PyPy3) 0.19 C (gcc 15.2.1) 0.1
Am I done?
NO! Of course not. This is just my foray into compiler engineering. I will not be making any more of these IGCSE Pseudocode interpreters; I will continue to maintain this one till the day I die. Please send bug reports! It will help all of us!
I will be working on a proper compiler that lowers an AST down to assembly, and a proper interpreter with a bytecode VM.
Oh also, my Computer Science teacher said that he’ll use this to teach Pseudocode to his grade 10 class, and by extension, the cohort. Yay! I’m not useless anymore, I guess. Stay tuned for a part 3 where I actually roast my code…if I find the motivation to write it.